February 18th, 2022 | by Piotr Zięba
Pagination: Server-Side vs. Client-Side | Dev's Case Study

Table of contents
What are all advantages and disadvantages of having pagination implemented on the front-end side? To illustrate my idea I will follow up with a case study.
But before I get to the substance, however, I want to explain the context and the background of this topic. It showed up when I was thinking about the sense of Redux and having a global state at all… My biggest worry was that usually when I had the opportunity to deal with Redux it didn’t bring me features that actually were as “game-changing” as it was offered. I mean – time travel debugging, undo/redo, state persistence, and power of selectors. Usually, it was just a layer for getting data and saving it – for me, useless and redundant. In one of my previous projects, I am quite sure that we easily could have removed this layer with no tears. Additionally, I’ve always had a lot of doubts about having all data in the “global” state. Usually, API was designed “per view” so actually having all these data in the state was completely useless…
So it inspired me to think about architecture where there is no pagination, filters, and search on the server-side. Also, API is very simple – delivers data and all transformations are done on the client-side. Let’s think about this scenario and consider all pros and cons of having pagination on the client-side.
TL;DR
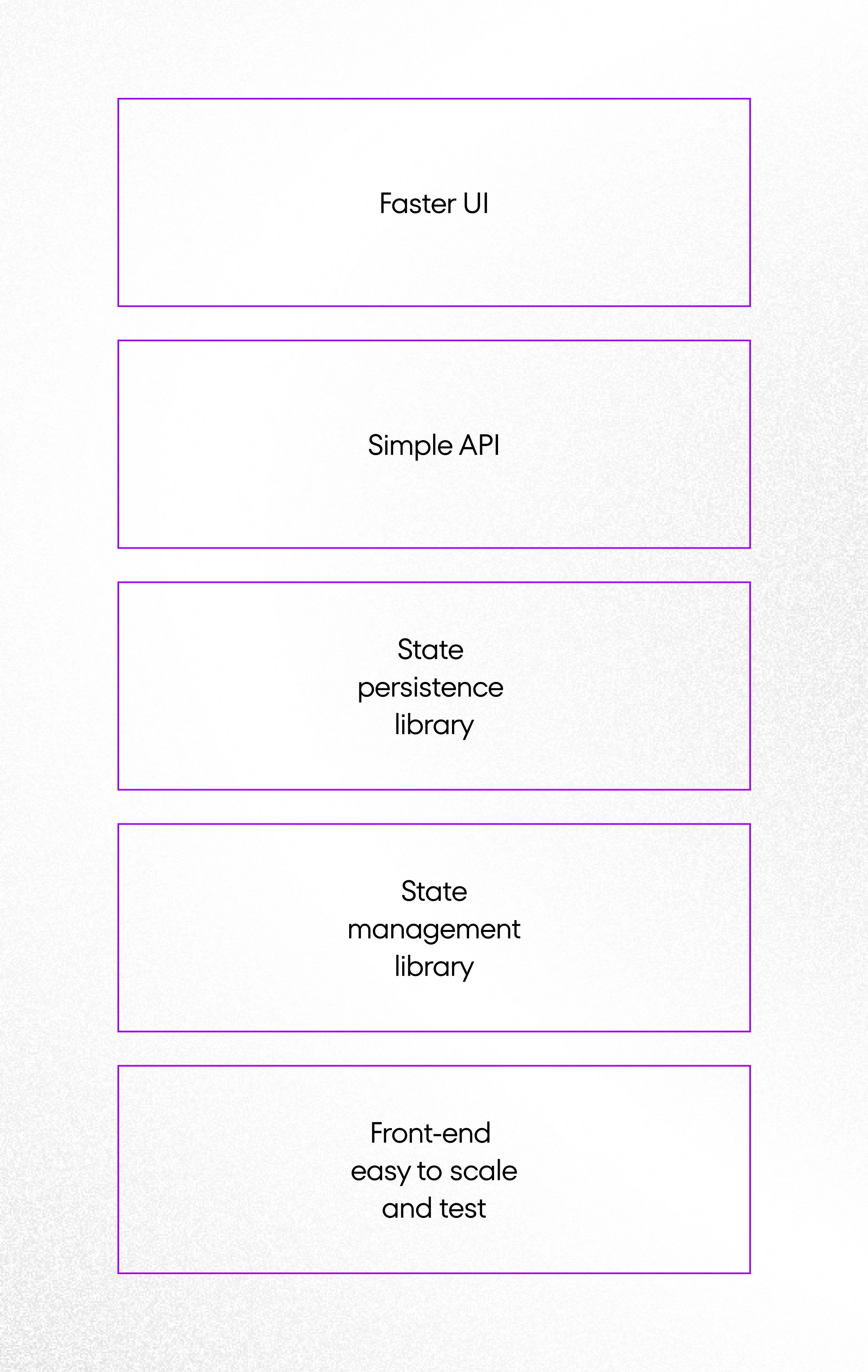
Advantages of pagination on front-end site:
- faster UI – faster rerenders and user interaction – as whole data is on the front end,
- simple API – a lot of implementation moved to the front-end – filtering, sorting, searching, data transformations,
- offline first easier to implement – you can boot your app with state persistence library,
- you can use the state management library and use all its features (time travel, debugging, selectors),
- front-end easy to scale and test.

Disadvantages of pagination on front-end site:
- slower data transmission – the thicker volume of data you send, the slower transmission you have,
- db queries might be slow – generally, it might be a bad solution for systems where there is a lot of data,
- it’s harder to scale system – you might end up with a strange hybrid which will complicate your system and make it harder to maintain,
- more complicated implementation – you need some state management library,
- more memory usage and CPU usage on the front-end,
- rare connection with back-end – bad choice for collaboration tools.


What is Pagination?
Pagination is no more than splitting a whole bunch of data into chunks. Generally, it is done for the following reasons:
- to optimize data queries and transformations – the larger volume, the more time we need to provide calculations,
- to speed up data transmission – crucial when we deal with really large data or really bad Internet connection,
- to optimize client-side rendering – displaying a large set of nodes in the DOM (Document Object Model) causes serious UI performance issues – usually, you just end up with a laggy interface.
Server-side vs. Client-side Pagination
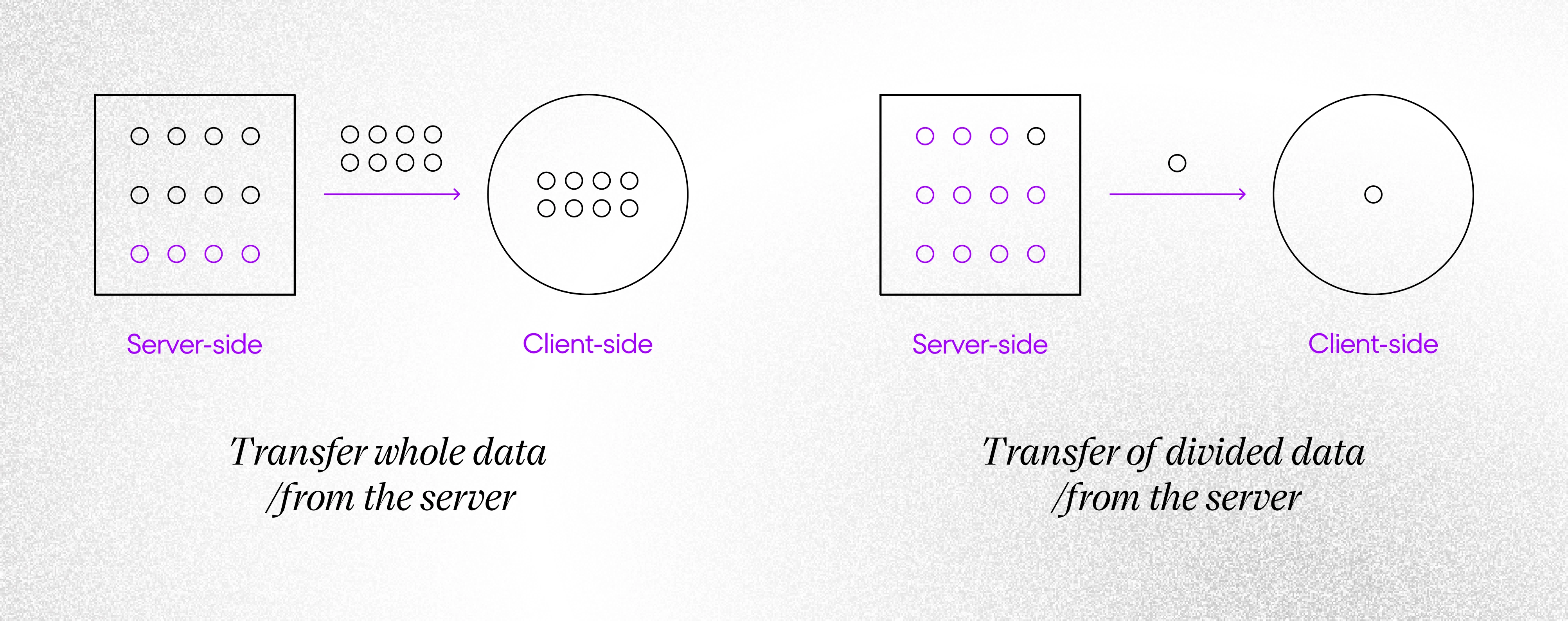
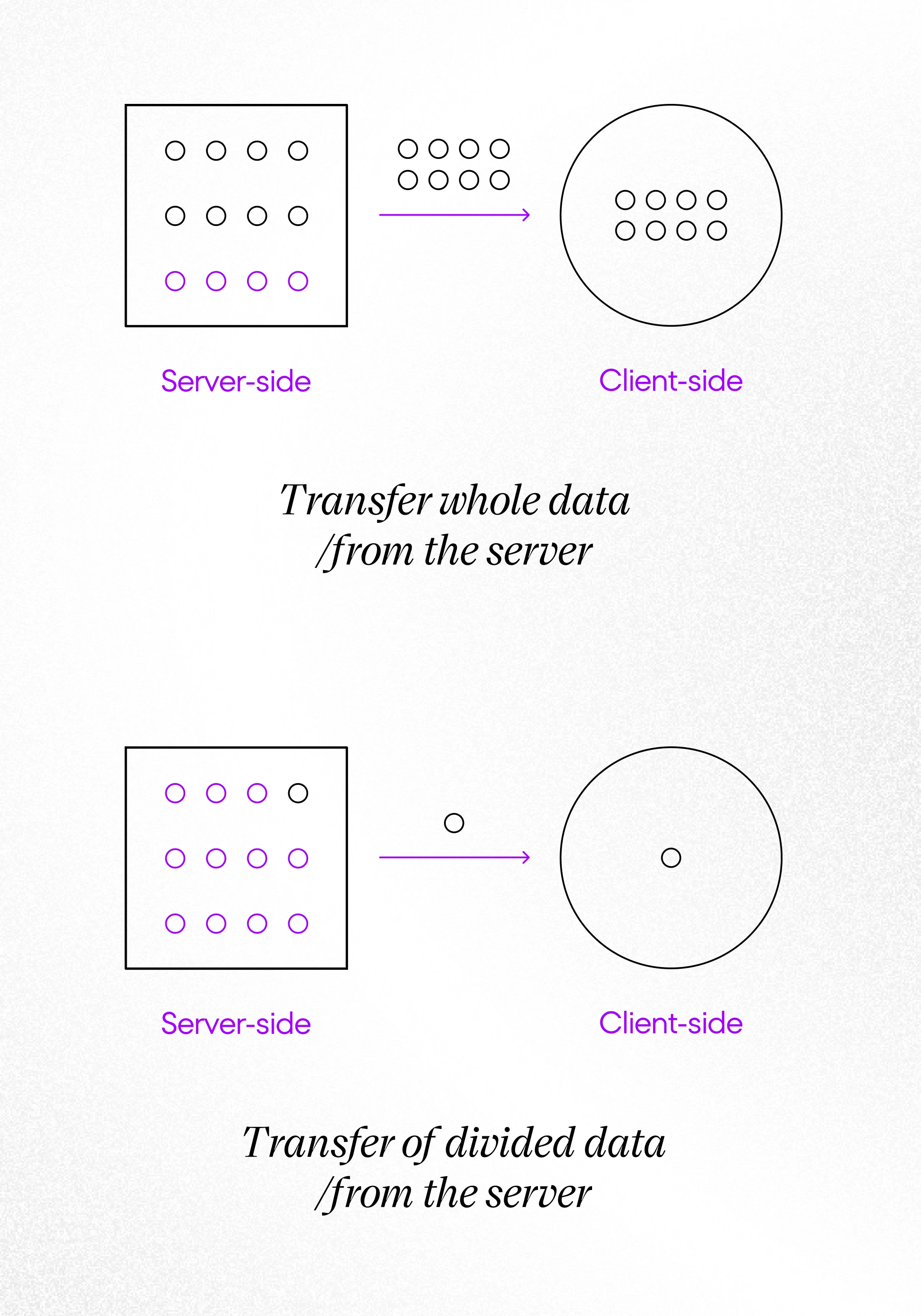
At first glance, there should not be any doubts about this question. These three issues can be solved in 100% with server-side pagination. But we need to take into account also some other circumstances, and apparently, it might turn out that client-side pagination is a much better solution for your project.
Case Study
Case study assumptions:
- client-side pagination, filtering, and search,
- simple API = authentication and CRUD operations,
- no data matching (JOINS) on the server-side,
- Redux state management library.
Client-side pagination
This is crucial in considered architecture. If we want to take the most of Redux, we need all data on the client-side. Pagination will be handled in the state’s slice. Additionally, we will have access to whole data to easily implement such features like filtering, sorting, and searching on the front-end side.
Simple API
The idea of moving pagination logic to the client-side is followed by the idea to make API as simple as it is possible. So I consider only relevant staff: security – authentication, and CRUD operations. It’s really important not to make any data transformations (instead of reducing some fields which don’t have to be exposed for the client).
We use Redux
Without handling pagination and some db data transformations on the server-side, we need to handle it somehow on the client. For that, we can use Redux. As it is widely documented on the Internet it might be the best choice. Using documented and standard solutions always wins.
We just need to model data in the slice wisely for pagination and implement some actions for changing pages. We can also look for some solutions on the web if we don’t know how to start.
For data transformations, we implement the selector’s layer. Selectors are just pure functions that take data from different state slices and combine them together. If you have some problems with redundant recalculations, you can use reselect library or just use the useMemo/useCallback hooks. Useful might be also some functional library like Ramda – it has a lot of functions for data transformations. Additionally, if we worry about request time, we can implement store persistence.
Solution architecture and its advantages
Let’s see how would the architecture of such a solution looks like. Thanks to the Redux concept we can easily distinguish the following different layers:
- API access layer – functions which are responsible for fetching data,
- store’s state – where we put whole data received from back-end and wrap it up with pagination logic,
- selectors – our pure functions which are responsible for doing magic with back-end raw data,
- views – react components that are responsible for displaying data.
Data flow
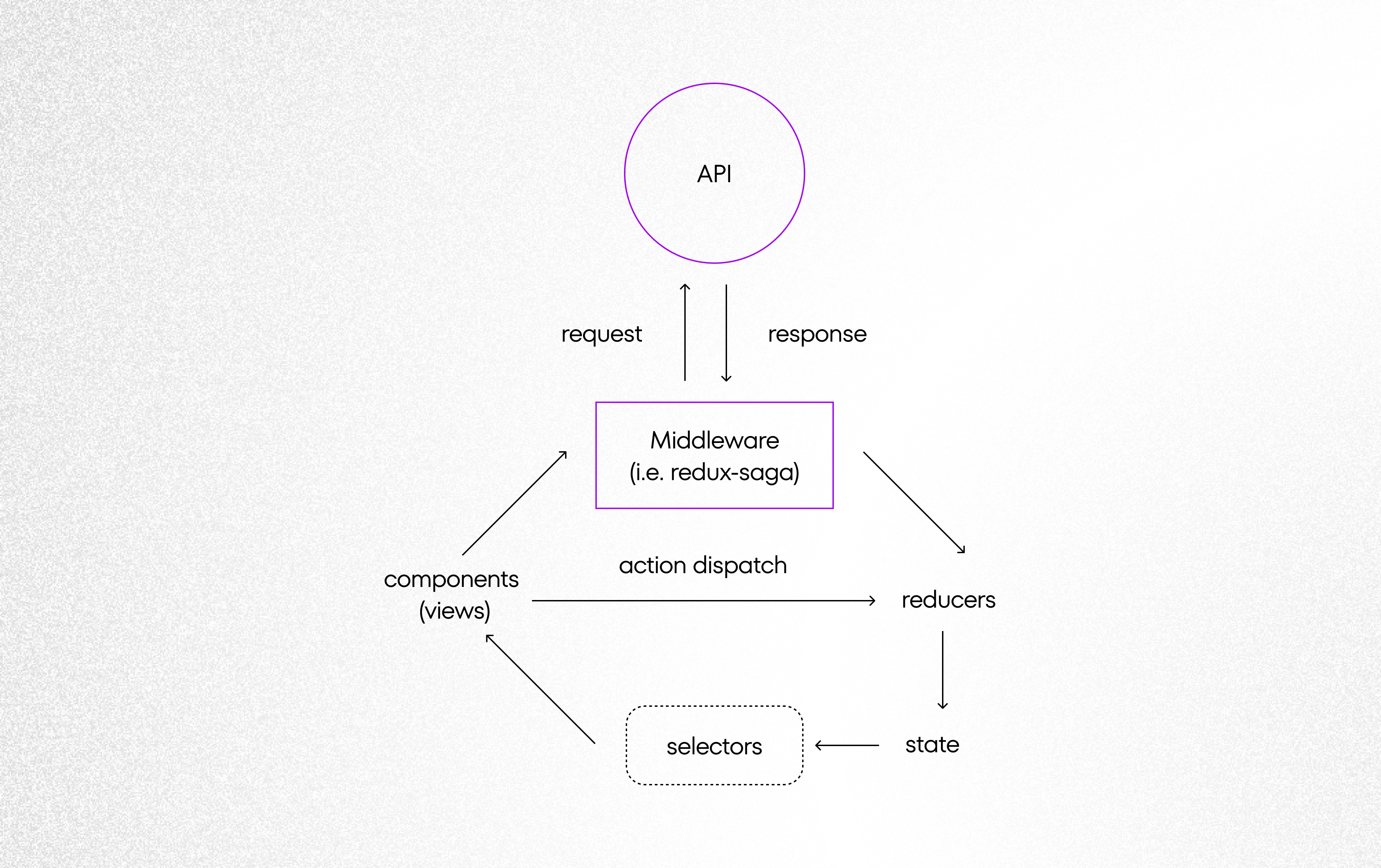
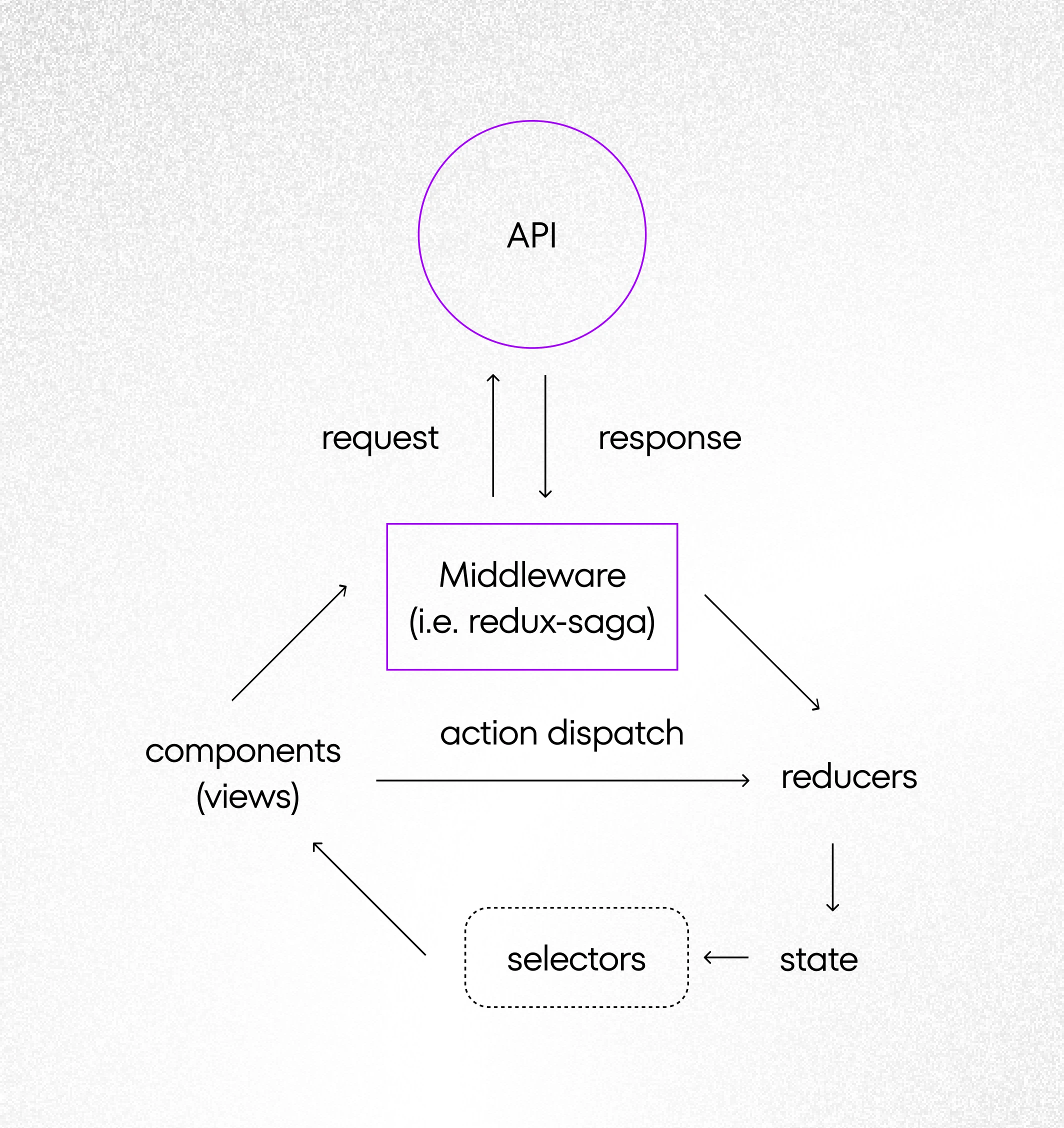
Such Separation of Concerns gives a lot of business and technical advantages.
From the technical perspective, giving access to the whole data makes the front-end more powerful. Now many features can be implemented only by the front-end team.
Devs and teams
Consider the following use case. You have two tables: Devs and Teams.
A team is just a group of developers. There are already implemented two endpoints – for getting developers and getting teams.
Then you receive a feature request – you have to display developers assigned to teams. The whole implementation is only on the front-end side.
You just need to derive data that you already have in the store. For that, you can just implement a new selector. From a technical perspective, it is very easy to implement and easy to test. Additionally, we don’t have to engage back-end developers and from the business perspective, we are saving their time and using it for some other tasks which are more unchallengeable.
Testing
Another important thing is that such architecture implies the way how you test it. The separation is clear and if you want to test different parts of architecture using unit tests you have no doubts.
If you want to test it for more functionality, this also should not be a problem as you are free to mock some business logic of filtering and pagination, etc. For unit testing, you can use Jest and for functional testing react-testing-library which exposes an extremely powerful API for testing UI. What’s more, in this scenario also we use Redux as it is meant to be – the store is global and it should be global because data which is coming from the server is not directly associated with a certain view it is totally generic and actually selectors are responsible for adapting data to a certain view.
User experience
From the user experience perspective also the UI is more responsive, as data is not transferred from the server with each user action. You can also implement store persistence functionality which saves stored data to the local storage, makes data available from the beginning and makes the app offline first. I think that such a scenario would perfectly fit some dashboards where you display visualizations of different datasets.
Tradeoffs and Caveat
When I read the previous sections I thought that I might be taken as a psycho fan of Redux and client-side pagination. To introduce some equality to my more immense thought, I say something about tradeoffs of keeping whole data at the client-side.
I would also like to point out that each case should be really deeply studied individually because every case is different. Of course, some common business cases determine the common architecture patterns but I strongly emphasize that you shouldn’t start planning architecture by choosing the stack and libraries you want to use. The right order is:
- deep analysis of business requirements,
- discussion with colleagues from front-end and back-end,
- choosing architecture and stack.
You have to remember that a wrong decision might be expensive. Now I would like to point out some reasons why you shouldn’t go in the client-side pagination direction:
- you have really heavy data,
- you have a really bad internet connection,
- you are integrating your system with others,
- you have a stronger backend team,
- your app is oriented on collaboration and you constantly need fresh data.
Remember also that you should look at the application as a whole system because the move of some logic from back-end to front-end does not eliminate anything; it is just moving a balance point to a different place. This functionality still has to be implemented!
Good luck!
***
If you have any questions, comments, or suggestions – feel free to contact me!


